
In last week’s post we talked about how inbound links layer on top of content to help search engines make their ranking decisions. While those are the two most important factors in a successful SEO campaign, the technical structure of a website can be a huge detriment to your efforts if not handled correctly. In case you missed it, you can read all about it here.
Ingredient 3: Tech Structure
We’ve talked about content, we’ve talked about links, but we haven’t yet talked about how search engines “consume” all of this information in order to make a ranking decision. This is where you may have heard the term “spiders” or “robots” in the past.
In simple terms, search engines use a software application that visits sites, indexes content, and moves on to visit all links on that single webpage, repeating the process over and over again.
This is how search engines create a picture of the overall web, and the foundation of how they use content and links to drive ranking decisions.
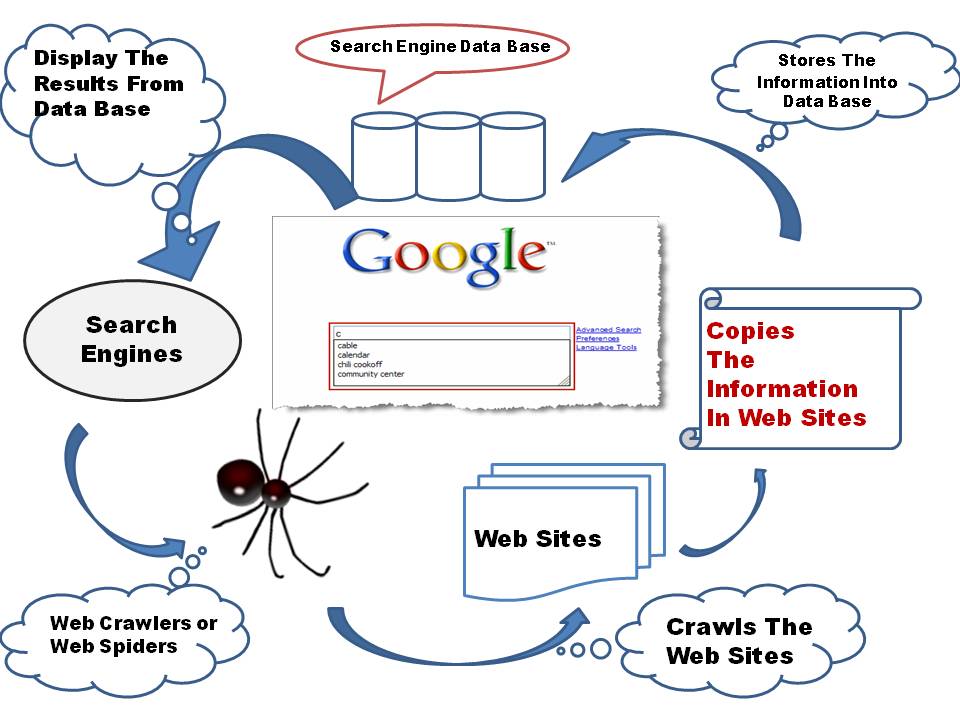
Now that we’ve covered how search engines are able to index billions of pages, we can talk about how technical structure can impact that. An internet bot is just a piece of software. It has no eyes or ears, and it’s not all that smart—in fact it doesn’t know anything about anything; it’s basically a glorified bean counter.
All of the content you’re reading on this blog is powered by Hypertext Markup Language (HTML), styled using Cascading Style Sheets (CSS), and enhanced using JavaScript (JS), and that’s just the “front end” of the web. Behind the scenes things get a lot more complex.
Let’s imagine we’re an internet bot and we visit BobsAcmeWidgets.com. The owner of the site, Bob, wants to rank for “Acme Widgets” to drive e-commerce traffic to his site. As the bot, you enter the site and first thing you notice is the title of the site:
<title>Bob’s</title>
Not very descriptive. Since we’re a bot, we don’t know what “Bob” means, and there’s zero mention of “Acme Widgets.” Next up we take a look at the header—this part should help: “We sell the highest quality Acme Widgets online.”
Eureka! As a bot we now have something to work with. Wait, nevermind. Bob wanted to use images for his headers, so the code shows the following:
<a href=http://www.bobsacmewidgets.com/page2.html><img src=”../header1.jpg” /></a>
Since we’re a bot, we can’t see—no eyes, remember? All we can tell is that there is a link to “page2.html” using an image called “header1.jpg.” At this point we still have no clue that Bob’s website is about Acme Widgets, outside of the single indicator of the URL itself.
While this is an elementary example of things that can make it hard for search engines to index your site, it shows off how important it is. Bob could have the best content in the world, and great backlinks, but if the search engine can’t “see” it in a way it understands, it will not rank it.
Some real world examples where the tech structure of a client site has hindered their SEO efforts include:
- The website is “hard-coded” and does not have a Content Management System (CMS), so adding new high quality content is prohibitive since it has to go through Information Technology (IT).
- The CMS is limited, so marketers can’t update titles, URL structure, or categorical structure.
- Because of privacy concerns on a secure portion of the site, IT has made the entire website “noindex, nofollow”—basically the return to sender of SEO.
- The site relies on complex code to run, overly relying on things like AJAX, Flash, or Javascript to present information. This in turn makes it hard for the internet bot to discern what exactly the content is.
- Imagery is overly used to add to the aesthetics of the site, robbing pages of important pieces of content.
There are a lot of deeper concerns with the technical approach to SEO, but the point remains the same: If you’re working in a business where marketing and IT cannot align on a way to make the site SEO-friendly, it is going to worsen the effectiveness of your other efforts.
Next week: The most important piece of a successful SEO campaign



